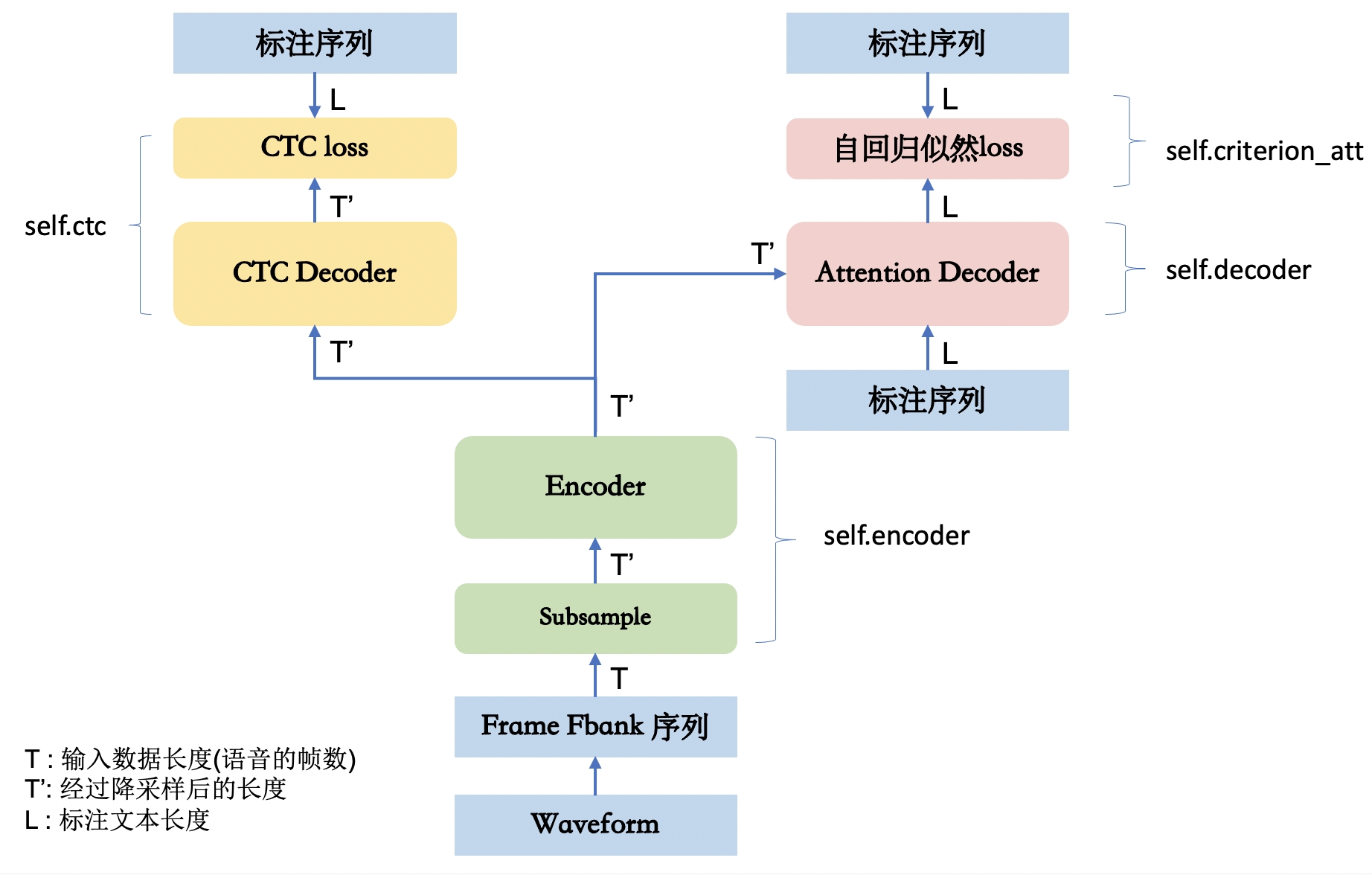
C++ – 使用cuda api获取本机显卡数量和显卡信息
1 使用cuda api获取本机显卡数量和显卡信息
我们可以在C++中结合CUDA API获取本机显卡数量以及每一个显卡的Memory Clock Rate、Memory Bus Width、Peak Memory Bandwidth等信息。
使用cudaGetDeviceCount函数返回连接到此系统支持的CUDA设备数量,然后循环每一个设备获取相应的信息,示例代码如下:
#include <iostream>
#include "cuda_runtime.h"
int main()
{
int gpu_devices_num;
cudaError_t err = cudaGetDeviceCount(&gpu_devices_num);
if (err != cudaSuccess)
{
std::cout << "Error Message : " << cudaGetErrorString(err) << std::endl;
}
std::cout << "GPU num : " << gpu_devices_num << std::endl;
for (int i = 0; i < gpu_devices_num; ++i)
{
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
std::cout << "Device Number: " << i << std::endl;
std::cout << " Device name: " << prop.name << std::endl;
std::cout << " Memory Clock Rate (KHz): " << prop.memoryClockRate << std::endl;
std::cout << " Memory Bus Width (bits): " << prop.memoryBusWidth << std::endl;
std::cout << " Peak Memory Bandwidth (GB/s): " << 2.0 * prop.memoryClockRate * (prop.memoryBusWidth / 8) / 1.0e6 << std::endl;
}
return 0;
}
输出结果:
GPU num : 1
Device Number: 0
Device name: NVIDIA GeForce GTX 1070
Memory Clock Rate (KHz): 4004000
Memory Bus Width (bits): 256
Peak Memory Bandwidth (GB/s): 256.256
参考链接
欢迎扫码关注我的微信公众号,及时获取文章更新

本文作者:StubbornHuang
版权声明:本文为站长原创文章,如果转载请注明原文链接!
原文标题:C++ – 使用cuda api获取本机显卡数量和显卡信息
原文链接:https://www.stubbornhuang.com/2537/
发布于:2023年03月08日 13:32:54
修改于:2023年06月21日 17:06:07
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
文章末尾



评论
72