


深度学习 – 语音识别框架wenet源码wenet/utils/mask.py中的mask机制
在阅读工业级语音识别框架wenet的源码的过程中,wenet/utils/mask.py中提供的各种mask函数非常重要,其实现了wenet论文Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recog…
- 深度学习
- 2022-08-10

Transformer – 理解Transformer必看系列之,2 Positional Encoding位置编码与Transformer编码解码过程
转载自: 链接:https://www.ylkz.life/deeplearning/p10770524/ 作者:空字符 少量行文修改 1 引言 经过此系列上一篇文章Transformer - 理解Transformer必看系列之,1 Self-Attention自注意力机制与多头注意力原理的介绍,…
- Transformer
- 2022-08-02
深度学习 – NLP自然语言处理与语音识别中常用的标识符等的含义
1 NlP自然语言处理与语音识别中常用的标识符的含义 在NLP进行文本处理以及语音识别处理语音对应标签时我们经常会看到一些特殊的标识符,一些常见的标识符及其含义如下 <blank>/<BLANK>:表示空白符号; <unk>/<UNK>:低频词或未在词…
- 深度学习
- 2022-08-01
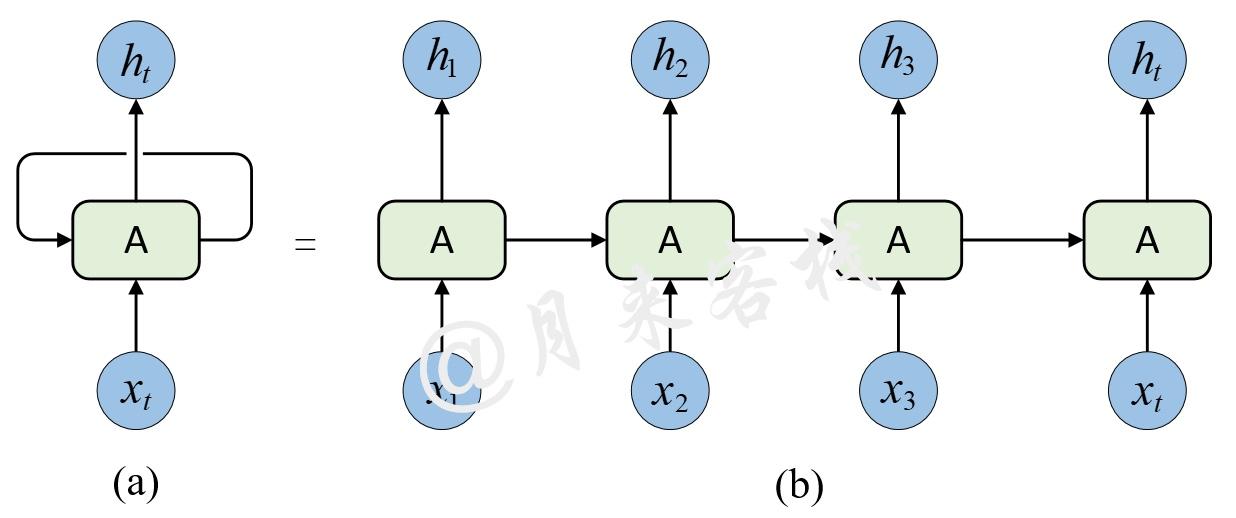
Transformer – 理解Transformer必看系列之,1 Self-Attention自注意力机制与多头注意力原理
转载自: 链接:https://www.ylkz.life/deeplearning/p10553832/ 作者:空字符 修改文章少量行文 1 引言 今天要和大家介绍的一篇论文是谷歌2017年所发表的一篇论文,名字叫做Attention is all you need,当然,网上已经有了大量的关于这…
- Transformer
- 2022-08-01

深度学习 – 以一个极简单的中英文翻译Demo彻底理解Transformer
转载自: 原文链接:https://zhuanlan.zhihu.com/p/360343417 作者:Algernon 少量行文修改。 Transformer并没有特别复杂,但是理解Transformer对于初学者不是件容易的事,原因因在于Transformer的解读往往没有配套的简单的demo,…
- Transformer
- 2022-07-29

深度学习 – 从矩阵运算的角度理解Transformer中的self-attention自注意力机制
转载自https://zhuanlan.zhihu.com/p/410776234 之前我对Transformer中的Self-Attention的机制也是看了很多遍论文,看了很多博文的解读,直到看到了这篇博文,让我醍醐灌顶,打通了任督二脉,果然将复杂问题讲复杂每个人都会,但是从基础的角度将复杂问题…
- Transformer
- 2022-07-20

深度学习 – Python实现CTC Decode解码算法Greedy Search Decode,Beam Search Decode,Prefix Beam Search Decode
在语音识别、OCR文字识别领域,我们在推理的最后一步就是从预测的概率矩阵中使用CTC解码算法找到可能性最大的序列。而常用的CTC解码算法一般有Greedy Search Decode(贪心搜索)、Beam Search Decode(束搜索)、Prefix Beam Search Decode(前缀…
- 深度学习
- 2022-07-19
深度学习 – 基础的Greedy Search和Beam Search算法的Python实现
假设当前词汇表中总共有5个词汇,现在有一个概率矩阵需要解码为词序列,词序列中包含10个词,以下通过Greedy Search Decoder和Beam Search Decoder对该词序列分别进行解码。 1 Greedy Search import numpy as np # greedy dec…
- 深度学习
- 2022-07-18
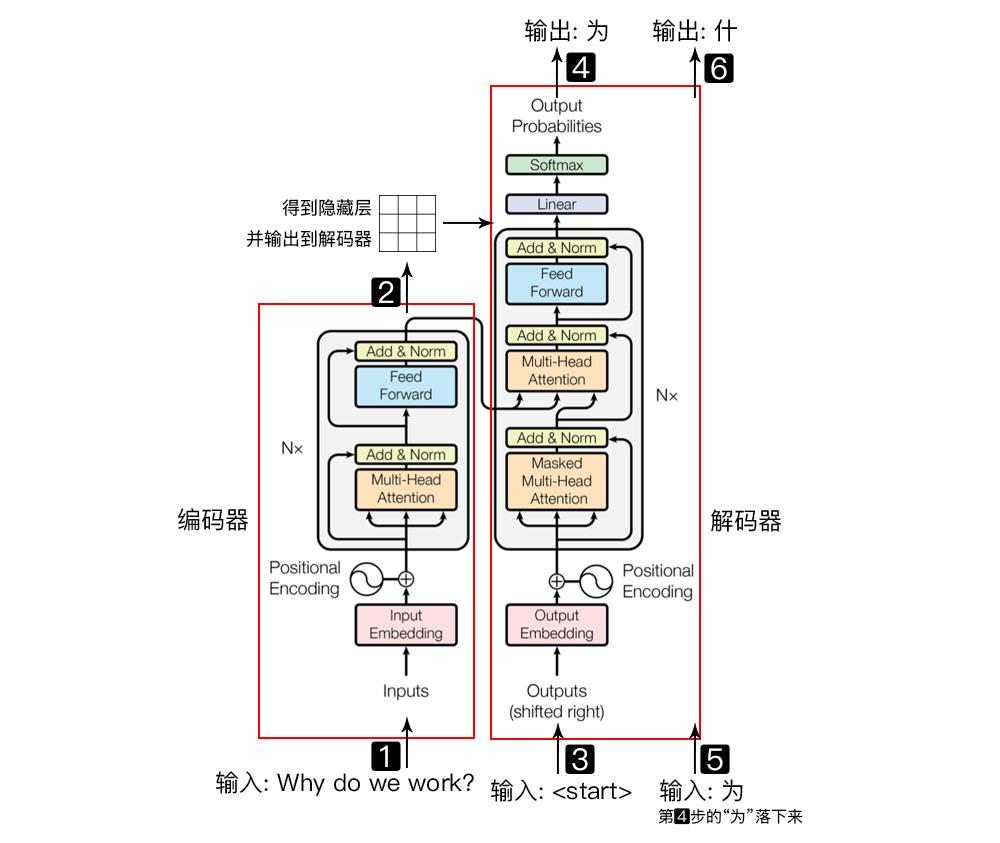
深度学习 – Transformer详解
转载自: 链接:https://wmathor.com/index.php/archives/1438/ 作者:wmathor Transformer 是谷歌大脑在2017年底发表的论文Attention Is All You Need中所提出的 seq2seq 模型。现在已经取得了大范围的应用和扩…
- Transformer
- 2022-07-16

深度学习 – Transformer详细注释
译自: https://nlp.seas.harvard.edu/2018/04/03/attention.html http://nlp.seas.harvard.edu/annotated-transformer/ 在过去的五年里,Transformer一直被很多多关注。本篇文章以逐行实现并详细…
- Transformer
- 2022-07-15

深度学习 – 通俗理解Beam Search Algorithm算法
1 Beam Search Algorithm 在本文中会尽量以通俗易懂的方式介绍Beam Search Algorithm的原理。 在机器翻译领域(Encoder-Decoder模型),将一种语言翻译成另外一种语言时,我们首先需要对源语言的单词序列进行编码,然后通过深度学习模型训练和推理得到中间输…
- 深度学习
- 2022-07-14

深度学习 – 经典的卷积神经网络(CNN)模型结构
转载自:http://shiyanjun.cn/archives/1974.html 本文主要简单介绍在卷积神经网络发展过程中,一些经常用的改进模型,主要包括LeNet-5、AlexNet、VGGNet、GoogLeNet、ResNet、DenseNet、ZFNet这7个模型。本文不会非常深入讲解各…
- 深度学习
- 2022-07-08