深度学习 – 从矩阵运算的角度理解Transformer中的self-attention自注意力机制
转载自https://zhuanlan.zhihu.com/p/410776234
之前我对Transformer中的Self-Attention的机制也是看了很多遍论文,看了很多博文的解读,直到看到了这篇博文,让我醍醐灌顶,打通了任督二脉,果然将复杂问题讲复杂每个人都会,但是从基础的角度将复杂问题讲简单真的是能力,瑞思拜!
本文会对转载的博文的一些措辞进行调整和修改,并加入新的部分,如果要看原文,请移步原文链接。
大部分的读者在初次看Transformer中的Self-Attention模块时应该都是比较懵的,而Self-Attention是Transformer的最核心的思想,Self-Attention难以理解的部分主要是对其中的查询矩阵Q,键矩阵K,值矩阵V三个矩阵的不理解,不过我们可以先不要关注其复杂的高维矩阵运算,我们可以从基本的矩阵运算以及其背后的几何意义作为切入点理解Self-Attention机制。
我们可以先回忆基础的线性代数的知识点。
- 向量的内积是什么?如何计算向量内积?向量的几何意义是什么?
- 一个矩阵W与其自身的转置矩阵相乘,其运算结果有什么意义?
1. Self-Attention的神级理解
本节,我们首先分析Transformer中最核心的部分,我们从公式开始,将每一都绘制成图,方便读者理解。
Self-Attention最核心的公式如下,
其实这一个公式中蕴含了很多个点,我们一个一个来讲,请读者跟随我的思路,从最核心的部分入手,细枝末节的部分会豁然开朗。
假如上面的公式很难理解,那么下面的公式读者能否知道其意义是什么?
我们先抛开Q,K,V三个矩阵不谈,self-Attention最原始的形态其实长上面这样。那么这个公式到底是什么意思呢?我们一步一步讲。
那么
代表什么意思?
我们知道,矩阵由规则排列的向量组成,一个矩阵乘以它自己的转置矩阵,其实可以看成当前矩阵的向量分别与其转置矩阵的向量计算内积。(此时脑海里想起矩阵乘法的口诀,第一行乘以第一列、第一行乘以第二列......嗯哼,矩阵转置以后第一行不就是第一列吗?这是在计算第一个行向量与自己的内积,第一行乘以第二列是计算第一个行向量与第二个行向量的内积,第一行乘以第三列是计算第一个行向量与第三个行向量的内积)
说到这里,我们看下我们在文章开头提出的问题,向量内积的几何意义是什么?
问:向量内积的几何意义?
答:向量内积的几何意义可以表征两个向量之间的夹角;当一个向量为单位向量,而另一向量不为单位向量,则表示为另一向量在单位向量上的投影。
我们假设X=[x_{1}^{T} ,x_{2}^{T} ,x_{3}^{T} ],其中X为一个二维矩阵,x_{i}^{T}为一个行向量(很多教材或者框架会以列主序存储,这里按我们高中,大学的教学以行主序为例进行说明),参考下图,x_{1}^{T}对应“早”字embedding后的向量,x_{2}^{T}对应“上”字embedding后的向量,x_{3}^{T}对应“好”字embedding后的向量。
下图中运算模拟了XX^{T}的计算过程,

首先x_{i}^{T}分别与自己和其他两个行向量做内积(“早”的向量分别与“上”和“好”的向量做内积),得到了一个新的向量。我们回顾上文中解读的向量内积的几何意义:向量的内积表征两个向量的夹角,表征一个向量在另一个向量上的投影。那么新求解的向量有什么意义?我们可以把它当做行向量x_{1}^{T}在其他两个行向量上的投影,我们思考投影值大与投影值小有什么意义?
投影值越大,说明两个向量的相关性越高!
如果两个向量的夹角为90度,则这两个向量线性无关,完全没有相关性!
更进一步理解,如果这个向量是词向量,是词在高维空间的数值映射,那么词向量之间的高度相关性说明了什么?是不是在一定程度上表示(不是完全)在关注当前词A的基础上,也会给词B更多的关注!!!
上面说明了一个行向量运算的意义,那么矩阵XX^{T}的计算意义是什么?矩阵XX^{T}是一个新的矩阵,我们从行向量内积的角度进行扩展,矩阵XX^{T}保存了每个向量与自己和其他矩阵所有向量进行内积运算的结果。(PS.看到这里了,就有很有意思了,应该没有不懂了吧!)
看到这里,基本上可以理解softmax(XX^{T} )X中XX^{T}的意义了,那么softmax(XX^{T} )的意义是什么呢?我们看下图

我们回忆softmax的公式,
softmax的意义主要是归一化,softmax操作之后,行向量的值的和为1,我们再想Attention机制的核心是什么?
加权求和
那么权重从哪里来?就是这些归一化之后的数字。当我们关注“早”这个字的时候,我们应该分配0.4的注意给它本身,剩下的分配0.4关注力给“上”,0.2的关注力给“好”。
行文至此,我们仿佛已经拨开了一些迷雾,公式softmax(XX^{T} )X已经理解了左侧的softmax(XX^{T} ),那么为什么还要右乘一个X,完整的公式究竟表示什么?我们接着以上的计算,继续看下图

我们取softmax(XX^{T} )的一个行向量为例,这一行向量与X的一个列向量相乘,表示什么?
观察上图,行向量与X的第一个列向量相乘,得到了一个新的行向量,且这个行向量与X的维度相同。
在新的向量中,每一个维度的数值都是由三个词向量在这一维度的数值加权求和得来的,这个新的行向量就是"早"字词向量经过注意力机制加权求和之后的表示。
一张更形象的图是这样的,图中右半部分的颜色深浅,其实就是我们上图中黄色向量中数值的大小,意义就是单词之间的相关度(回想之前的内容,相关度其本质是由向量的内积度量的)!

如果您坚持阅读到这里,相信对公式softmax(XX^{T} )X已经有了比较深刻的理解,我们接下来解释原始公式中一些细枝末节的东西。
2 QKV矩阵
在第一节中叙述中,我们的例子中并没有出现Q,K,V的字眼,因为这不是公式中最本质的内容,那么Q,K,V到底是什么?
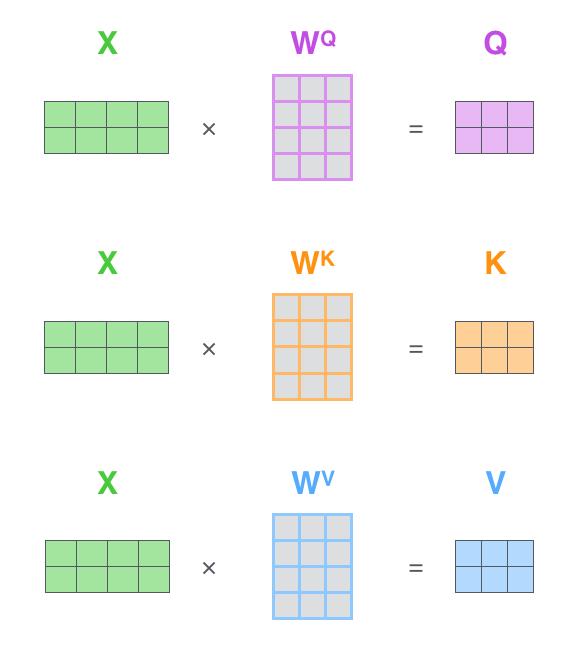
论文中或者许多博文中经常提及的Q,K,V矩阵其实就是X与参数矩阵W^Q,W^K,W^V的乘积,本质上都是X的线性变换。
那么为什么不直接使用X,而要对其进行线性变换呢?
当然是为了提升模型的拟合能力,参数矩阵W^Q,W^K,W^V都是可训练的,起到一个缓冲的效果。
如果你真正读懂了前文的内容,读懂了softmax(XX^{T} )X运算中深层次的意义,相信也可以举一反三理解所谓的W^Q,W^K,W^V矩阵。
3 self-attention的计算过程
self-attention本质上就是一系列矩阵运算。那么它的的计算过程是怎样的呢?
我们以输入为x^1对应输出为b^1为例,进行说明,如下图。

针对以上动图涉及的计算过程,我们在下图进行一一对应,
Self-Attention整体的计算过程用如下图进行归纳

参考链接
欢迎扫码关注我的微信公众号,及时获取文章更新

本文作者:StubbornHuang
版权声明:本文为站长原创文章,如果转载请注明原文链接!
原文标题:深度学习 – 从矩阵运算的角度理解Transformer中的self-attention自注意力机制
原文链接:https://www.stubbornhuang.com/2225/
发布于:2022年07月20日 9:03:30
修改于:2024年03月08日 13:47:17
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






评论
72